【Python数据分析与处理 实训02】 ---2012欧洲杯信息分析(数据过滤与排序)
本文共 2023 字,大约阅读时间需要 6 分钟。
【Python数据分析与处理 实训02】 —2012欧洲杯信息分析(数据过滤与排序)
探索2012欧洲杯信息
对于下面的数据集进行简单的一些数据的分析训练:

若需要源数据请私信~
读取数据
euro12 = pd.read_csv("G:\Projects\pycharmeProject\大数据比赛\泰迪智能科技\data\Euro2012.csv",sep=",",index_col=0)print(euro12.head(10)) 通过给定的数据集,可以发现原始数据中的第一列为team,第一行为字段列名,可以在读取的时候加入
index_col=0可将第一列在读取时看成行名,这样数据集就变成每一个队伍的欧洲杯数据,当然也可以不使用该参数,根据具体情况来看。

1.将数据写出成一个excel文件
euro12.to_excel('G:\Projects\pycharmeProject\大数据比赛\泰迪智能科技\data\Euro12.xls') 通过
to_excel()可以将结果集保存为excel表格

2.只选取Goals这一列。
print(euro12['Goals'])

3.有多少球队参与了2012欧洲杯?
print(euro12['Team'].nunique())
之前统计的时候,我们都使用
unique先进行去重操作,然后再进行取size,今天介绍一个新方法nunique(),n代表了个数number,可以直接获取去重数据后的个数。

4.该数据集中一共有多少列(columns)?
print(euro12.shape[1])

5.将数据集中的列Team, Yellow Cards和Red Cards单独存为一个名叫discipline的数据框。
discipline = euro12[['Team', 'Yellow Cards', 'Red Cards']] # 方式一print(discipline)discipline = euro12.loc[:, ['Team', 'Yellow Cards', 'Red Cards']] # 方式二print(discipline)
单独存为一个名叫discipline的数据框,简单的说就是提取所需要的有效列,可以通过切片的方式提取列后赋予一个新的变量来实行。

6.对数据框discipline按照先Red Cards再Yellow Cards进行排序。
print(discipline.sort_values(['Red Cards', 'Yellow Cards'], ascending=False))
排序操作,sort_values中参数传入要进行排序的列,当有多个列的时候使用[]包含起来。

7.计算每个球队拿到的黄牌数的平均值。
print(discipline.groupby('Team').agg({ 'Yellow Cards': 'sum'}).mean()) 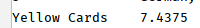
8.找到进球数Goals超过6的球队数据。
index1 = euro12['Goals'] > 6print(index1)print(euro12.loc[index1, :]) # 数据框的第四种索引方式:根据逻辑值进行访问

9. 选取以字母G开头的球队数据。
isG = euro12['Team'].str[0] == "G"print(isG)print(euro12.loc[isG,:])

10. 选取前7列。
print(euro12.iloc[:,0:7])


11. 选取除了最后3列之外的全部列。
print(euro12.iloc[:,:-3])


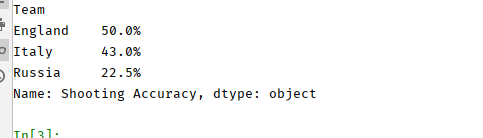
12.找到英格兰(England)、意大利(Italy)和俄罗斯(Russia)的射正率(Shooting Accuracy)。
# 方法一a = (euro12['Team'] == "England") | (euro12['Team'] == "Italy") | (euro12['Team'] == "Russia")print(a)print(euro12.loc[a,"Shooting Accuracy"])
对于逻辑访问的应用 ,首先筛选出符合条件逻辑。然后再查询Shooting Accuracy。

# 方法二euro12.set_index('Team',inplace=True)print(euro12.loc[['England','Italy','Russia'],'Shooting Accuracy']) 我们还可以使用直接提取的方式,但是首先要做一个转变,就是将Team列设定为index,上面一种方法实际上在查询的时候,也是按照逻辑值为true的index去查询的,所以在这里,使用第二种方法,我们直接将Team列设为行索引去查询。
转载地址:http://oghq.baihongyu.com/
你可能感兴趣的文章
matlab文件管理
查看>>
Printer Queue UVA - 12100
查看>>
【并发编程】实现多线程的几种方式
查看>>
Nginx简介
查看>>
Nginx的Gzip功能
查看>>
mybatis的基础配置
查看>>
基于.Net Core 5.0 Worker Service 的 Quart 服务
查看>>
ASP.net 常用服务器控件
查看>>
Azure Storage 系列(四)在.Net 上使用Table Storage
查看>>
我成为 Microsoft Azure MVP 啦!(ps:不是美国职业篮球)
查看>>
异步编程基础
查看>>
[模板] 带修莫队
查看>>
* 二维数组的使用
查看>>
a instanceof A:判断对象a是否是类A的实例。如果是,返回true;如果不是,返回false
查看>>
abstract关键字的使用
查看>>
创建线程的方式四:使用线程池
查看>>
算法题:获取一个字符串在另一个字符串中出现的次数
查看>>
算法题:获取两个字符串中的最大相同子串
查看>>
Calendar日历类(抽象类)的使用
查看>>
Asp.Net Core&Jenkins持续交付到Windows Server
查看>>